- Published on
Production RAG: Chunking Strategies, Hybrid Search, Reranking and Evaluation
- Authors

- Name
- Yassine Handane
- @yassine-handane
NB07 : Production RAG
In NB03 we built a basic RAG pipeline with a simple retriever and default chunking. This notebook focuses on what separates a toy RAG from a production-grade one.
We cover three pillars:
- Chunking strategies: how to split documents accurately for embedding
- Advanced retrieval: hybrid search (BM25 + dense) with reranking
- Evaluation: measuring RAG quality with LLM-as-judge metrics
Document used throughout: Lilian Weng's blog post Why We Think (May 2025)
Stack: LangChain, HuggingFace embeddings (all-MiniLM-L6-v2), OpenRouter (arcee-ai/trinity-large-preview:free)
!pip install -q langchain langchain-community langchain-huggingface \
langchain-text-splitters sentence-transformers \
rank-bm25 flashrank langchain-classic langchain[openai] tiktoken
import os
import warnings
warnings.filterwarnings("ignore")
from dotenv import load_dotenv
load_dotenv()
OPENROUTER_API_KEY = os.getenv("OPENROUTER_API_KEY")
Section 1 : Chunking Strategies
What it is
Chunking is the process of splitting a large document into smaller pieces that can be individually embedded and retrieved. Each chunk becomes one vector in the vectorstore.
What problem it solves
A full document embedded as a single vector produces a representation that averages out all its content. The resulting vector is too generic to match specific questions precisely. Smaller, well-calibrated chunks produce focused vectors that retrieve accurately.
How it connects to NB03
In NB03 we used RecursiveCharacterTextSplitter with default parameters as a baseline. In production, two questions matter: how do we measure chunk size accurately, and how do we preserve document structure in chunk metadata?
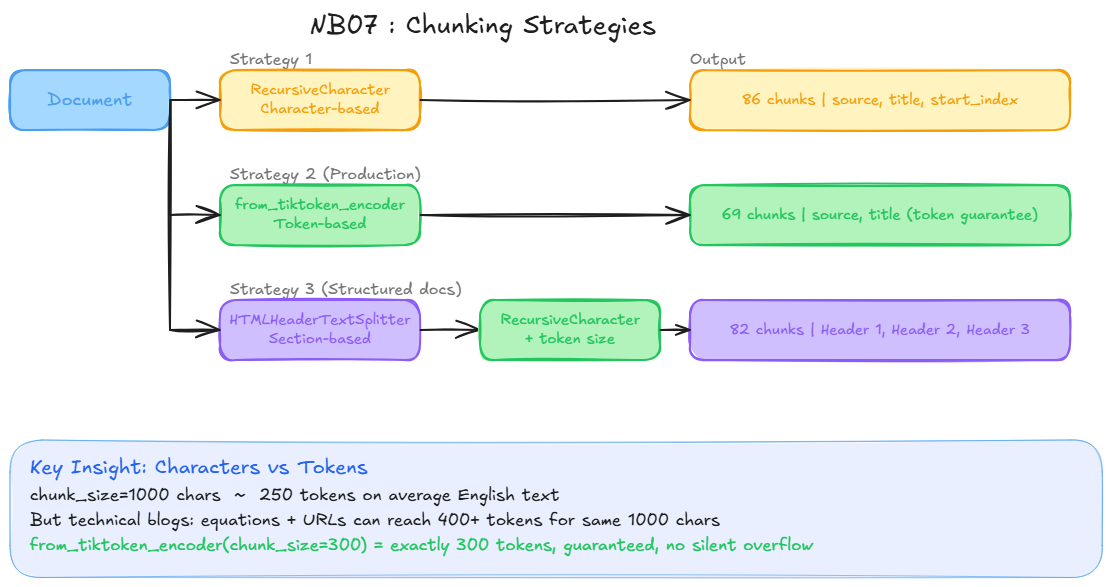
Three strategies compared
| Strategy | Unit | Metadata | Use case |
|---|---|---|---|
RecursiveCharacterTextSplitter | Characters | source, title | General text, baseline |
from_tiktoken_encoder | Tokens | source, title | Production, context window guarantee |
HTMLHeaderTextSplitter + two-step | Tokens | Headers H1/H2/H3 | Structured HTML documentation |
Key insight: characters vs tokens
LLMs reason in tokens, not characters. In English, 1 token ≈ 4 characters on average, but technical content with long function names, URLs, or code can shift that ratio significantly.
from_tiktoken_encoder gives a hard guarantee: chunk_size=300 means exactly 300 tokens, regardless of content type. Without this, you risk silently exceeding the model context window.
Concrete risk: 5 chunks at chunk_size=1000 characters ≈ 1250 tokens. But on a technical blog with equation-heavy sections, those same chunks could be 2000+ tokens, causing silent truncation.
HTMLHeaderTextSplitter: when to use it
Splits on HTML headers (<h1>, <h2>, <h3>) and propagates header labels into chunk metadata. Each chunk knows which section it belongs to. This enables metadata filtering at retrieval time.
Limitation on blogs: sections are unequal in size (8 to 4772 characters in our case). The two-step pattern fixes this: split by headers first, then re-split oversized sections with RecursiveCharacterTextSplitter. Each final chunk inherits the parent header metadata.
HTMLHeaderTextSplitter
Section "Memory" (4000 chars) {Header 2: "Memory"}
|
RecursiveCharacterTextSplitter
|
chunk_1 (300 tokens) {Header 2: "Memory"}
chunk_2 (300 tokens) {Header 2: "Memory"}
chunk_3 (300 tokens) {Header 2: "Memory"}
Diagram
import requests
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter, HTMLHeaderTextSplitter
URL = "https://lilianweng.github.io/posts/2025-05-01-thinking/"
# Load document
loader = WebBaseLoader(web_paths=(URL,))
docs = loader.load()
print(f"Document loaded: {len(docs[0].page_content)} characters")
# Strategy 1: RecursiveCharacterTextSplitter (character-based)
char_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
add_start_index=True
)
char_chunks = char_splitter.split_documents(docs)
# Strategy 2: RecursiveCharacterTextSplitter (token-based) -- used for the rest of the notebook
token_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-2",
chunk_size=300,
chunk_overlap=50
)
token_chunks = token_splitter.split_documents(docs)
# Strategy 3: HTMLHeaderTextSplitter + two-step split
html_content = requests.get(URL).text
html_splitter = HTMLHeaderTextSplitter(
headers_to_split_on=[
("h1", "Header 1"),
("h2", "Header 2"),
("h3", "Header 3"),
]
)
html_chunks = html_splitter.split_text(html_content)
html_chunks_with_metadata = [c for c in html_chunks if c.metadata]
two_step_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-2",
chunk_size=300,
chunk_overlap=50
)
two_step_chunks = two_step_splitter.split_documents(html_chunks_with_metadata)
# Comparison
print(f"\nStrategy 1 - Character-based: {len(char_chunks)} chunks")
print(f"Strategy 2 - Token-based: {len(token_chunks)} chunks")
print(f"Strategy 3 - Two-step (HTML + tokens): {len(two_step_chunks)} chunks")
print(f"\nStrategy 1 metadata: {char_chunks[0].metadata}")
print(f"Strategy 2 metadata: {token_chunks[0].metadata}")
print(f"Strategy 3 metadata: {two_step_chunks[5].metadata}")
# Index token-based chunks for the rest of the notebook
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vectorstore = InMemoryVectorStore.from_documents(token_chunks, embeddings)
print(f"Vectorstore ready: {len(token_chunks)} chunks indexed")
Section 2 : Advanced Retrieval
2.1 Hybrid Search
What it is
Hybrid search combines two complementary retrieval strategies: dense (semantic) and sparse (keyword-based).
What problem it solves
Dense retrieval (bi-encoder) is excellent for semantic similarity but weak on exact rare terms. If you search for "budget forcing", the vector retriever may not rank the most relevant chunk first because it searches for meaning, not exact tokens.
BM25 (sparse) does the opposite: it counts exact token frequencies with a correction for document length. Imbattable on specific terminology, blind to semantic meaning.
Query: "What is Reciprocal Rank Fusion?"
Dense retriever -> finds chunks about "merging search results" (semantic)
BM25 retriever -> finds chunks containing exact tokens "Reciprocal", "Rank", "Fusion"
How it connects to Section 1
Both retrievers work on the same token_chunks indexed in Section 1. BM25 builds an in-memory frequency index from the same chunks; the dense retriever uses the vectorstore.
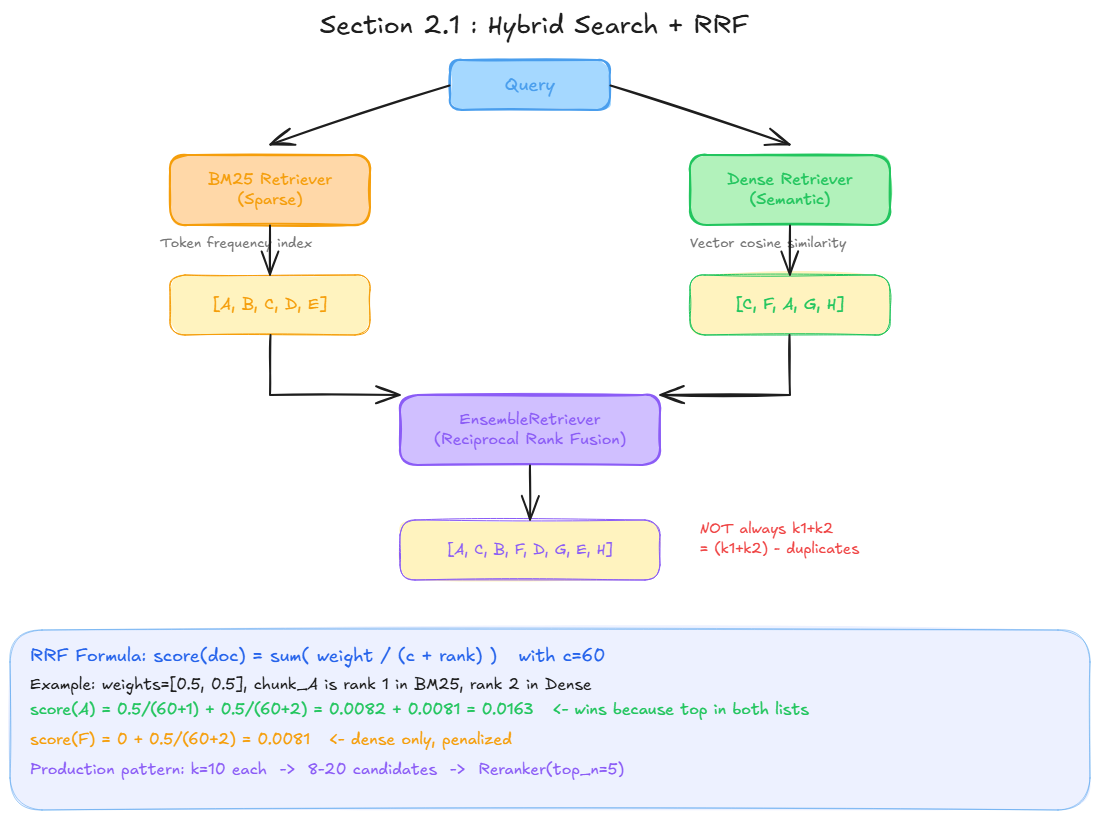
Reciprocal Rank Fusion (RRF)
BM25 scores (TF-IDF) and dense scores (cosine similarity) are not comparable. RRF ignores the raw scores and uses only the rank of each document in each list.
Formula: score(doc) = sum( weight / (c + rank) ) where c=60 (constant that softens the advantage of rank 1 over rank 2).
Example with k=5 each, weights=[0.5, 0.5]:
BM25: [A, B, C, D, E] Dense: [C, F, A, G, H]
score(A) = 0.5/(60+1) + 0.5/(60+2) = 0.0163 <- top: appears in both lists
score(C) = 0.5/(60+3) + 0.5/(60+1) = 0.0161
score(B) = 0.5/(60+2) + 0 = 0.0081 <- BM25 only, penalized
score(F) = 0 + 0.5/(60+5) = 0.0077 <- Dense only, penalized
A chunk that ranks well in both lists wins. A chunk present in only one list is penalized.
Important: the final result count
With k=5 on each retriever, the result is NOT always 10. The formula is:
final_count = (k_bm25 + k_dense) - duplicates
In practice: 5+5=10 max, often 7-9 depending on overlap. EnsembleRetriever has no own k parameter. This variable count is handled by the reranker in Section 2.2.
Production pattern
k=10 on each retriever -> 8 to 20 candidates via RRF -> Reranker(top_n=5)
Diagram
from langchain_community.retrievers import BM25Retriever
from langchain_classic.retrievers import EnsembleRetriever
# Sparse retriever (keyword-based, no embedding model needed)
# Indexing happens here: from_documents builds the BM25 frequency index in memory
bm25_retriever = BM25Retriever.from_documents(token_chunks, k=5)
# Dense retriever (semantic, uses the vectorstore built in Section 1)
semantic_retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
# Hybrid retriever: RRF fusion of both
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, semantic_retriever],
weights=[0.5, 0.5]
)
# Compare the three retrievers on the same query
# Using a query with a precise technical term to highlight the difference
query = "What is budget forcing ?"
bm25_results = bm25_retriever.invoke(query)
dense_results = semantic_retriever.invoke(query)
hybrid_results = ensemble_retriever.invoke(query)
print("=== BM25 (sparse) ===")
for doc in bm25_results[:2]:
print(doc.page_content[:150])
print()
print("=== Dense (semantic) ===")
for doc in dense_results[:2]:
print(doc.page_content[:150])
print()
print("=== Hybrid (RRF) ===")
for doc in hybrid_results[:2]:
print(doc.page_content[:150])
print()
2.2 Reranking
What it is
Reranking is a post-retrieval step that rescores the candidates returned by the retriever using a more precise but slower model.
What problem it solves
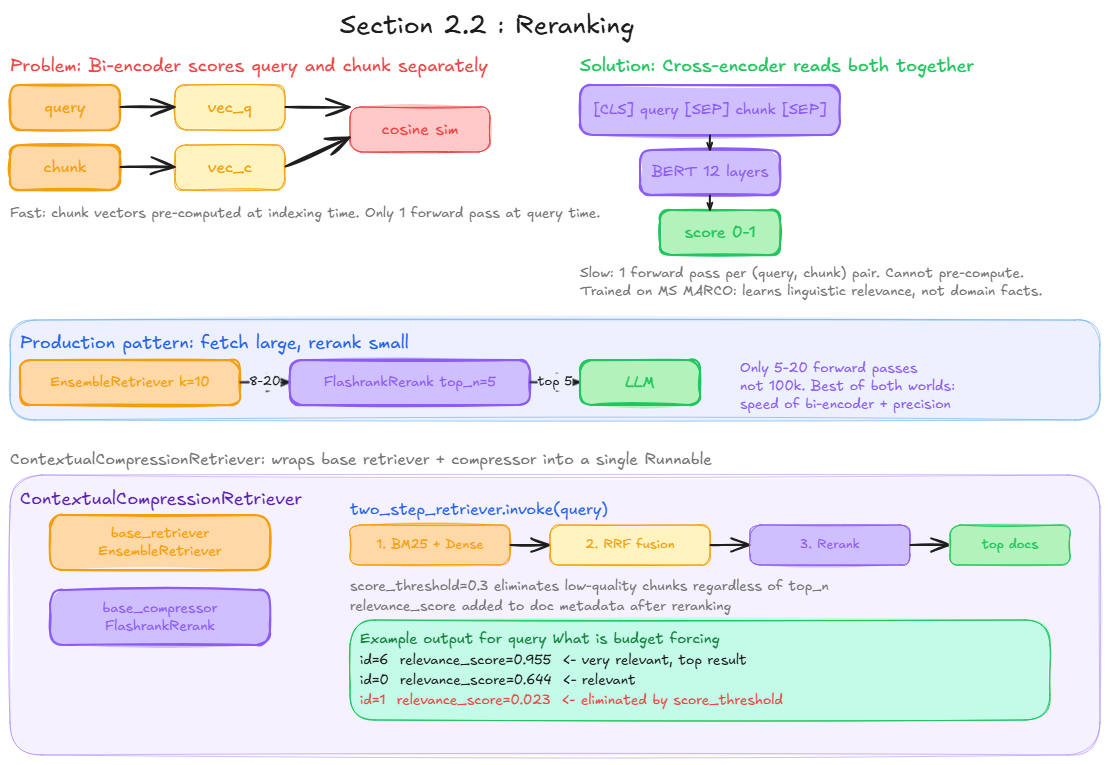
Hybrid search uses a bi-encoder: query and chunk are encoded separately, and the score is a cosine similarity between two independent vectors. Fast and scalable, but approximate.
A cross-encoder reads the pair (query, chunk) together in a single forward pass and produces a direct relevance score. It can capture fine-grained interactions between query tokens and chunk tokens.
Bi-encoder (retrieval)
query -> vector_q ->
cosine_similarity -> score
chunk -> vector_c ->
Cross-encoder (reranking)
[CLS] query [SEP] chunk [SEP] -> transformer -> relevance score
Architecture of a reranker
A reranker is a BERT-style encoder-only transformer trained as a binary classifier on labeled pairs (query, document, label) where label=1 means relevant. The raw probability score (0 to 1) is used to sort candidates, not the binary label.
Models like ms-marco-MultiBERT-L-12 are trained on MS MARCO (millions of real Bing queries annotated for relevance). The patterns learned transfer well to unseen domains because the model learns linguistic relevance, not domain-specific facts.
Why not use a cross-encoder for all retrieval?
Because it requires one forward pass per (query, chunk) pair. On 100k chunks, that is 100k forward passes per query. The bi-encoder computes chunk vectors once at indexing time; only the query vector is computed at inference. The cross-encoder cannot pre-compute anything.
Production pattern
EnsembleRetriever (k=10 each)
|
8 to 20 candidates <- variable count due to RRF deduplication
|
FlashrankRerank(top_n=5, score_threshold=0.3)
|
exactly top 5 results <- guaranteed count, filtered by quality
|
LLM
score_threshold eliminates low-relevance chunks regardless of top_n. A chunk with score 0.02 (bibliography, navigation text) is discarded even if it is in the top 5.
ContextualCompressionRetriever
LangChain wraps the reranker in ContextualCompressionRetriever: a standard Runnable that combines a base retriever with a document compressor. From the outside it looks like any other retriever: .invoke(query) returns a list of documents.
Diagram
from langchain_community.document_compressors.flashrank_rerank import FlashrankRerank
from langchain_classic.retrievers.contextual_compression import ContextualCompressionRetriever
# Cross-encoder reranker (local, no API key required)
reranker = FlashrankRerank(top_n=5, score_threshold=0.3)
# Final retriever: hybrid search + reranking
two_step_retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=ensemble_retriever
)
# Test the full pipeline on the same query
# Each result now includes a relevance_score from the cross-encoder
results = two_step_retriever.invoke(query)
for doc in results:
print(f"Score: {doc.metadata['relevance_score']:.3f}")
print(doc.page_content[:200])
print()
Section 3 : Evaluation
What it is
Evaluation measures the quality of a RAG pipeline in a repeatable, automated way. Without metrics, "it looks better" is not a reliable production argument.
What problem it solves
RAG quality has multiple dimensions that can fail independently: the retrieval can be good while the LLM hallucinates, or the LLM can answer correctly while the retrieval was irrelevant. A single metric misses these failure modes.
LLM-as-judge
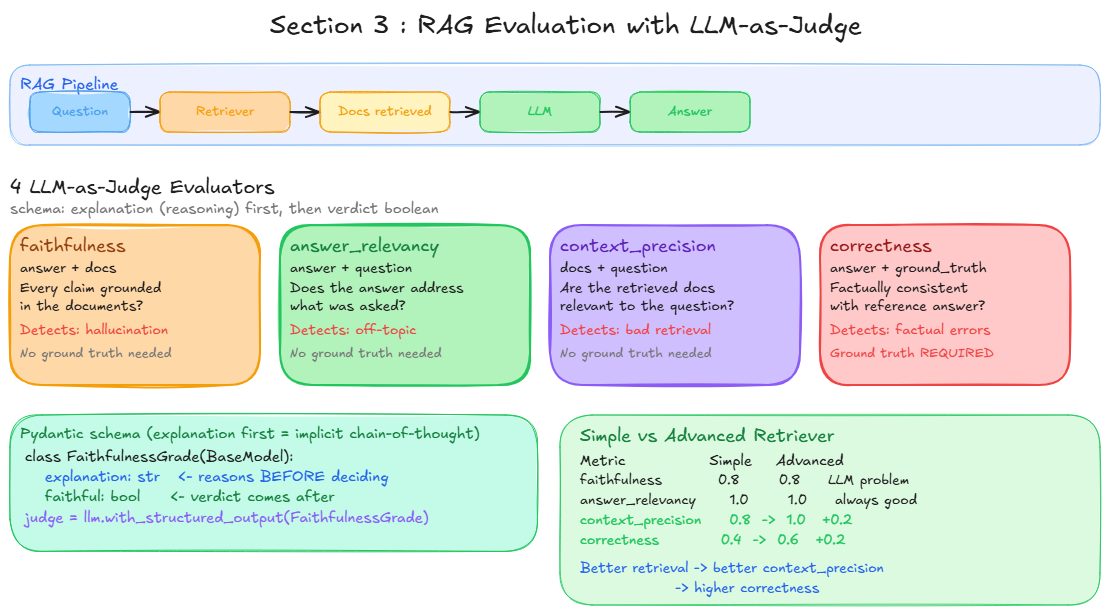
We use an LLM as evaluator with with_structured_output. For each criterion, the LLM receives specific inputs and returns a structured verdict. We use a Pydantic schema with explanation first (forces reasoning before verdict) then a boolean.
This approach is equivalent to RAGAS metrics:
| RAGAS metric | Our implementation | Inputs | Needs ground truth |
|---|---|---|---|
faithfulness | evaluate_faithfulness | answer + docs | No |
answer_relevancy | evaluate_answer_relevancy | answer + question | No |
context_precision | evaluate_context_precision | docs + question | No |
correctness | evaluate_correctness | answer + ground_truth | Yes |
The 4 metrics explained
Faithfulness: Is the answer grounded in the retrieved documents? Detects hallucination. The LLM checks if every claim in the answer has support in the docs.
Answer Relevancy: Does the answer address the question? Detects off-topic responses. Compares answer to question only, regardless of truthfulness.
Context Precision: Are the retrieved documents relevant to the question? Evaluates retrieval quality. A perfect answer generated from irrelevant docs would score low here.
Correctness: Is the answer factually consistent with the ground truth? Compares against a human-written reference answer.
Key distinction between faithfulness and correctness: a response can be faithful (grounded in docs) but incorrect (the docs themselves were wrong or incomplete). These two metrics catch different failure modes.
Diagram
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from pydantic import BaseModel
# LLM for RAG pipeline and evaluation
llm = ChatOpenAI(
api_key=OPENROUTER_API_KEY,
base_url="https://openrouter.ai/api/v1",
model="arcee-ai/trinity-large-preview:free"
)
parser = StrOutputParser()
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant that is a master in AI. Help the user based on the following context: {context}"),
("human", "{question}")
])
# RAG pipeline
# The retriever is called once, docs are reused for both context injection and evaluation
def format_context(docs) -> str:
return "\n\n".join(doc.page_content for doc in docs)
def rag_pipeline(question, retriever):
docs = retriever.invoke(question)
context = format_context(docs)
answer = (prompt_template | llm | parser).invoke({
"context": context,
"question": question
})
return {
"question": question,
"answer": answer,
"docs": docs
}
# Evaluation dataset
# Mix of precise queries (good for BM25) and semantic queries (good for dense)
eval_dataset = [
{
"question": "What is budget forcing ?",
"ground_truth": "Budget forcing is a technique that controls the length of a model's chain-of-thought reasoning by either forcefully lengthening it by appending the word 'wait', or shortening it by appending an end-of-thinking token or 'Final Answer:'."
},
{
"question": "Why does allowing models to think longer improve their performance ?",
"ground_truth": "Allowing models to think longer improves performance because it gives them additional compute at inference time to reason through problems step by step, which has been shown to boost performance beyond the capability limits obtained during training."
},
{
"question": "What is the STaR algorithm and how does it work ?",
"ground_truth": "STaR (Self-Taught Reasoner) is an iterative algorithm where the model generates chain-of-thought rationales, fine-tunes on those that lead to correct answers, and uses a rationalization process for failed attempts by generating CoTs conditioned on both the problem and the ground truth answer."
},
{
"question": "What are thinking tokens and why are they useful ?",
"ground_truth": "Thinking tokens are special implicit tokens inserted during training or inference that do not carry direct linguistic meaning but provide extra computation time for the model. They are useful because they expand computation by introducing more inference loops and act as an implicit form of chain-of-thought reasoning."
},
{
"question": "How does test-time compute compare to pretraining compute for improving model performance ?",
"ground_truth": "Test-time compute and pretraining compute are not 1-to-1 exchangeable. Test-time compute can close performance gaps on easy and medium questions but is less effective for hard problems. It is only preferable when inference tokens are substantially fewer than pretraining tokens."
}
]
# LLM-as-judge evaluators
# explanation field comes first: forces the LLM to reason before deciding (implicit chain-of-thought)
class FaithfulnessGrade(BaseModel):
explanation: str
faithful: bool
class AnswerRelevancyGrade(BaseModel):
explanation: str
relevant: bool
class ContextPrecisionGrade(BaseModel):
explanation: str
precise: bool
class CorrectnessGrade(BaseModel):
explanation: str
correct: bool
# Judge LLMs
faithfulness_llm = llm.with_structured_output(FaithfulnessGrade)
relevancy_llm = llm.with_structured_output(AnswerRelevancyGrade)
precision_llm = llm.with_structured_output(ContextPrecisionGrade)
correctness_llm = llm.with_structured_output(CorrectnessGrade)
# Prompts
faithfulness_prompt = ChatPromptTemplate.from_messages([
("system", """You are a RAG evaluation expert.
Check if the answer is grounded in the provided documents.
Every claim in the answer must be supported by the documents.
Return faithful=True only if no hallucination is detected."""),
("human", "ANSWER: {answer}\n\nDOCUMENTS: {docs}")
])
relevancy_prompt = ChatPromptTemplate.from_messages([
("system", """You are a RAG evaluation expert.
Check if the answer directly addresses the question asked.
Return relevant=True only if the answer is on topic and useful."""),
("human", "QUESTION: {question}\n\nANSWER: {answer}")
])
precision_prompt = ChatPromptTemplate.from_messages([
("system", """You are a RAG evaluation expert.
Check if the retrieved documents are relevant and useful for answering the question.
Return precise=True only if the documents contain information needed to answer."""),
("human", "QUESTION: {question}\n\nDOCUMENTS: {docs}")
])
correctness_prompt = ChatPromptTemplate.from_messages([
("system", """You are a RAG evaluation expert.
Check if the answer is factually consistent with the ground truth.
Return correct=True only if the answer matches the ground truth."""),
("human", "ANSWER: {answer}\n\nGROUND TRUTH: {ground_truth}")
])
# Evaluator functions
def format_docs_for_eval(docs):
return "\n\n".join(doc.page_content for doc in docs)
def evaluate_faithfulness(answer, docs):
grade = (faithfulness_prompt | faithfulness_llm).invoke({
"answer": answer,
"docs": format_docs_for_eval(docs)
})
return {"faithful": grade.faithful, "explanation": grade.explanation}
def evaluate_answer_relevancy(answer, question):
grade = (relevancy_prompt | relevancy_llm).invoke({
"answer": answer,
"question": question
})
return {"relevant": grade.relevant, "explanation": grade.explanation}
def evaluate_context_precision(docs, question):
grade = (precision_prompt | precision_llm).invoke({
"docs": format_docs_for_eval(docs),
"question": question
})
return {"precise": grade.precise, "explanation": grade.explanation}
def evaluate_correctness(answer, ground_truth):
grade = (correctness_prompt | correctness_llm).invoke({
"answer": answer,
"ground_truth": ground_truth
})
return {"correct": grade.correct, "explanation": grade.explanation}
# Evaluation runner
def run_evaluation(eval_dataset, retriever):
evaluations = []
for e in eval_dataset:
response = rag_pipeline(e["question"], retriever)
faith = evaluate_faithfulness(response["answer"], response["docs"])
relev = evaluate_answer_relevancy(response["answer"], response["question"])
prec = evaluate_context_precision(response["docs"], response["question"])
corr = evaluate_correctness(response["answer"], e["ground_truth"])
evaluations.append({
"question" : e["question"],
"answer" : response["answer"],
"faithfulness" : faith["faithful"],
"faithfulness_exp" : faith["explanation"],
"answer_relevancy" : relev["relevant"],
"answer_relevancy_exp" : relev["explanation"],
"context_precision" : prec["precise"],
"context_precision_exp" : prec["explanation"],
"correctness" : corr["correct"],
"correctness_exp" : corr["explanation"],
})
return evaluations
def summarize_evaluation(evaluations):
metrics = ["faithfulness", "answer_relevancy", "context_precision", "correctness"]
n = len(evaluations)
return {
metric: round(sum(e[metric] for e in evaluations) / n, 2)
for metric in metrics
}
# Compare simple retriever vs advanced retriever (hybrid + reranking)
results_simple = run_evaluation(eval_dataset, semantic_retriever)
results_advanced = run_evaluation(eval_dataset, two_step_retriever)
print("Simple retriever :", summarize_evaluation(results_simple))
print("Advanced retriever :", summarize_evaluation(results_advanced))
Results analysis
Metric Simple Advanced
faithfulness 0.8 0.8 <- same: hallucination comes from LLM, not retrieval
answer_relevancy 1.0 1.0 <- both always on topic
context_precision 0.8 1.0 <- +0.2: hybrid search retrieves more relevant docs
correctness 0.4 0.6 <- +0.2: better docs produce more accurate answers
Key takeaways:
context_precision improves from 0.8 to 1.0: hybrid search + reranking consistently retrieves the most relevant chunks. The causal chain is visible in the numbers.
correctness improves from 0.4 to 0.6: better retrieved context leads to better generated answers.
faithfulness stays at 0.8: hallucination is a generation problem, not a retrieval problem. Changing the retriever does not fix it. This is where guardrails (NB09) come in.
answer_relevancy is perfect on both: the LLM always answers the question asked, regardless of retrieval quality.